De hace un tiempo que estoy investigando el mundillo de los modelos de lenguaje grandes (Large Language Models) y la verdad al principio es todo un tema, ves mil términos, referencias y herramientas y no sabés para que sirve cada una, así que acá voy a compartir algunas de las cosas que me voy encontrando, tratando de definirlas y relacionándolas entre si.
Frameworks para hacer aplicaciones de IA
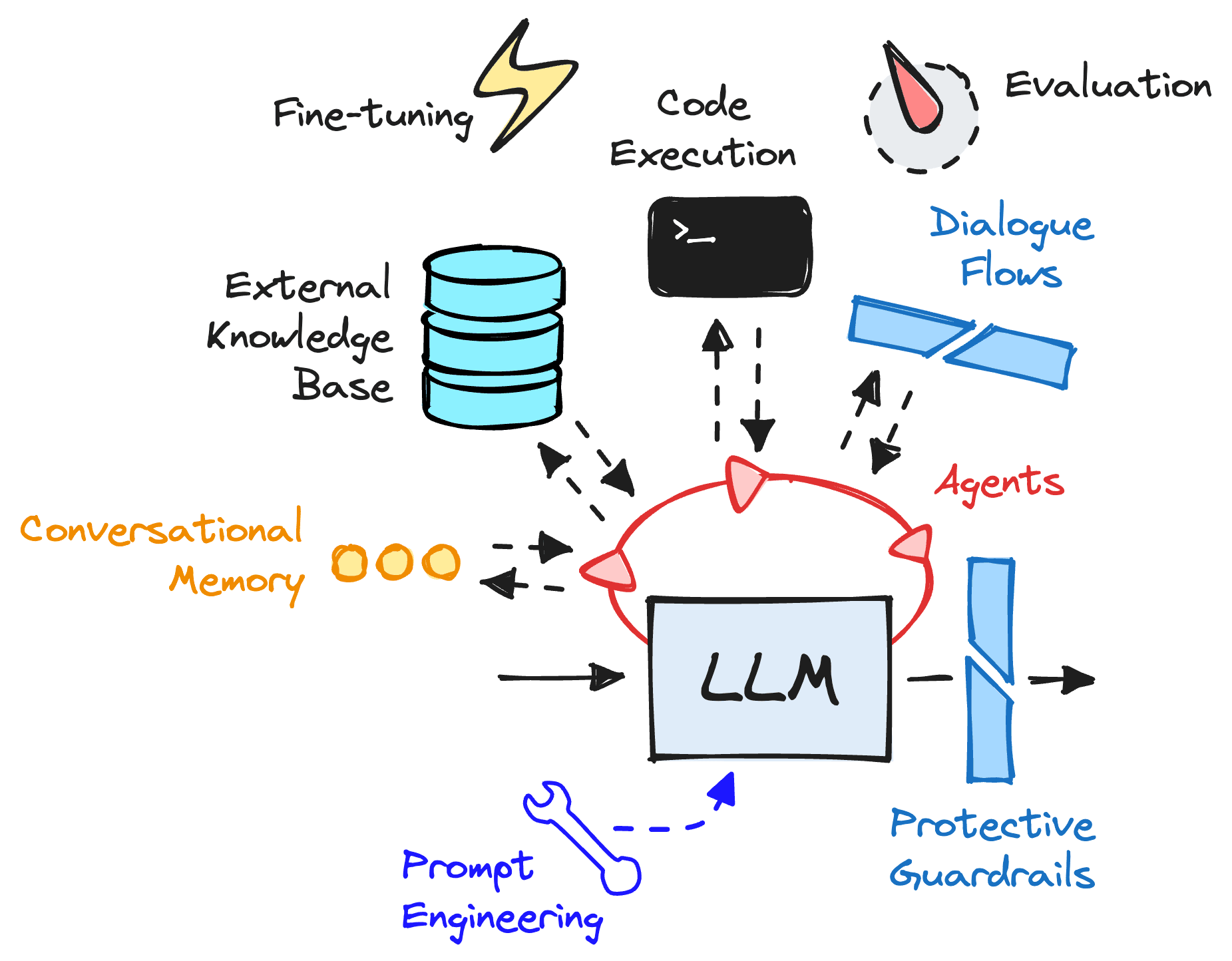
Los modelos de lenguaje lo único que saben hacer es predecir un texto a partir de un texto de entrada que le damos, todo el chiste de hacer chats, resúmenes, consultas a bases de datos, guardar memorias de conversaciones, acceder a datos privados para que me hable de mi situación o lo que sea son agregados que hay que hacer conectando distintas partes con herramientas externas como estas.
- LangChain: Framework para crear aplicaciones que combinan modelos de lenguaje con otras herramientas y servicios.
- LlamaIndex: Framework para indexar y consultar grandes volúmenes de datos usando modelos de lenguaje.
- SGLANG: Framework para construir y ejecutar aplicaciones de modelos de lenguaje, diseñado específicamente para la ejecución eficiente de programas estructurados que involucran modelos de lenguaje. Se enfoca en la optimización del rendimiento y escalabilidad.
Frameworks graficos:
Estos frameworks apuntan a un uso por parte de usuarios con menos conocimiento de programación, usualmente se montan sobre langchain o llamindex, haciendo una traducción grafica de las llamadas a estos frameworks de programación
- Flowise
- langflow
- anything llm
Evaluación y monitoreo
Evaluacion de productos llm:
- langsmith (propietario)
- Langfuse (open source)
- Lunary (open source)
- MLFlow: open source, para experimentos de ia en general,
Servidores de inferencia locales
A uno le copa charlar con chatgpt o el que sea pero… ¿Que pasaría que si les dijera que puedo tener un «chatgpt» en mi propia computadora? Esto sirve para explorar y estudiar el funcionamiento, a su vez que probar distintos modelos de lenguaje antes de poner en funcionamiento alguno en particular
- LLaMA.cpp: Implementación en C++ del modelo LLaMA, optimizado para ejecutar modelos de lenguaje LLaMA localmente.
- ollama: Servidor local para ejecutar y servir modelos de lenguaje, ideal para pruebas y desarrollo.
- GPT4All: Servidor local para ejecutar modelos GPT-4, ofreciendo control total sobre instancias de modelos.
Servidores de inferencia «industriales» (arme su propio server)
No es lo mismo tener un modelo de lenguaje funcionando en mi computadora que ofrecer un chat para miles de personas 24/7, acá vemos herramientas que permiten hacerlo a escala industrial.
- Ray Serve: Despliegue y escalado de modelos en entornos distribuidos, útil para aplicaciones que requieren alta disponibilidad.
- FastAPI con Hugging Face Transformers: API rápida para modelos de Hugging Face, ideal para aplicaciones web.
- Triton Inference Server: Servidor de inferencia para múltiples frameworks, enfocado en alto rendimiento y escalabilidad.
- ONNX Runtime: Motor de inferencia para modelos ONNX, optimizado para ejecutar modelos en diferentes hardware.
Servidores de inferencia externos
Si no quiero servir mi propio modelo de lenguaje puedo consumir el servicio, usualmente la gente usa el de chatgpt , pero hay otros que nos permiten usar otros modelos.
- Hugging Face Inference API: API en la nube para inferencia con modelos preentrenados de Hugging Face, cobran la contratación de cloud con gpu de AWS.
- OpenAI API: API para integrar modelos de lenguaje avanzados de OpenAI, como GPT-4.
- NLP Cloud: Servicio en la nube para inferencia de modelos de procesamiento de lenguaje natural.
- AWS Bedrock: Servicio de Amazon para acceder a modelos de lenguaje preentrenados en la nube.
- Together IA: Servicio de inferencia de modelos, cobra segun tokens de intercambio y tamaño del modelo utilizado
Librerías para programar modelos
Algunas librerias para crear modelos de redes neuronales pueden ser estas. (para crear de cero)
- PyTorch: Biblioteca flexible para diseñar y entrenar modelos de aprendizaje profundo.
- TensorFlow: Biblioteca para crear y desplegar modelos de aprendizaje profundo, con soporte para gráficos computacionales estáticos.
- Hugging Face Transformers: Biblioteca con modelos preentrenados para procesamiento de lenguaje natural, facilitando su uso en aplicaciones.
Formatos
Despues de entrenar un modelo es necesario llevar el resultado a algun entorno par aejecutarlo ¿Como se hace? Hay distintos formatos de archivos y no todo funciona con todo.
- PyTorch Script (.pt): Formato de PyTorch para guardar modelos entrenados.
- ONNX (Open Neural Network Exchange): Formato para representar modelos y permitir interoperabilidad entre diferentes frameworks.
- TensorFlow SavedModel: Formato de TensorFlow para exportar modelos completos, incluyendo arquitectura y pesos.
- GGML/GGUF: Formatos para guardar y compartir modelos de lenguaje, orientados a interoperabilidad.
¿Motores de optimización?
- Hugging Face Optimum: Biblioteca para optimizar el rendimiento de modelos Transformers, mejorando eficiencia de inferencia.
- NVIDIA TensorRT: Motor de inferencia para optimizar modelos de aprendizaje profundo en GPUs NVIDIA, centrado en velocidad y eficiencia.
En otro artículo voy a poner los modelos de lenguaje.